(Défoulement préalable.)
J’ai vomi beaucoup de bile sur Business Objects l’an dernier en mars et août. Comme je l’ai dit, je suis frustré de voir un outil conceptuellement excellent, qui à la base fonctionne, et n’est pas trop mal fichu, être plombé par :
- des erreurs ergonomiques atroces (ça s’améliore avec le temps) ;
- des régressions de fonctionnalités d’une version sur l’autre qui me font passer pour un con aux yeux de mes élèves de formation (de la 6.5 à XI R2 c’était un supplice ; ça va mieux avec XI 3) ;
- des bugs : un tableau qui se calcule mal est pénible (c’est tout de même rare), mais j’ai hurlé à cause des outils d’import-export du référentiel voire d’installation/désinstallation (!) qui déconnent complètement (ça a coûté cher à mes clients) ; évidemment de manière reproductible, et au deuxième ou troisième Service Pack ;
- une pléthore de produits annexes, achetés au fil du temps par BO, au point que le mystère plane sur les fonctionnalités du Performance Pack, à moins que ce soit le Productivity Management (ce syndrome est courant chez tout éditeur d'une certaine taille : SAP, Oracle...) ;
- un système de numérotation de versions illisible, rendant le point précédent encore plus douloureux (la stabilisation semble tout de même en cours) ;
- des décisions techniques parfois débiles ou dictées par la mode ;
- une architecture en forme de millefeuille Java, très lourd et complexe ;
- des délais d’expiration de session ou d’un des innombrables services internes réglés au plus juste, sources de moults messages d’erreur tous plus abscons les uns que les autres aux yeux des utilisateurs et de la perte directe d’heures de travail ;
- une documentation pléthorique mais trop lourde, et anti-pédagogique (avec une copie d’écran par tome, quand j’illustre mes supports de formation de deux par page) ;
- un paramétrage fin de l’apparence par intervention directe dans les fichiers de configuration
.xmlou.properties, voire directement les.jspdu site web (je préfère encore ça à la base de registres[1]) ; - SAP enfin, qui vient de racheter BO, ce qui augure mal de l’avenir — leur première action a été de déplacer tout le site de support, brisant non seulement les liens externes mais aussi les liens documentaires depuis leur propre produit (!!) ; cette abomination me reste encore en travers de la gorge, il y a des baffes qui se perdent ; enfin, le site de SAP a toujours été un labyrinthe sans nom complètement verrouillé, même quand on a des accès (chers payés).
(Fin du défoulement. Soyons positif.[2])
BO a réussi à s’imposer auprès de ses clients et à leur faire cracher autant d’argent (et avec SAP ça ne va pas s’arranger) pas uniquement par hasard. En comparant succinctement avec quelques produits concurrents, je me suis aperçu que BO possède quelques atouts difficiles à trouver ailleurs, surtout ensemble. Si vous connaissez un concurrent qui arrive à la cheville de BO sur ces sujets, je suis preneur !!!
La notion d’univers
(Voir le début de cet ancien billet pour un exemple.) Le principe consiste juste à stocker et masquer les tables, les jointures... nécessaires à l’interrogation des diverses bases de données dans un « univers » réutilisable. L’utilisateur ne manipule plus alors que des objets Facture, Quantité, Nom, Date, Région, etc. qu'il lâche dans des tableaux et, ô miracle, les calculs se font tous seuls, du moins dans les cas simples. Ne reste que la mise en page[3].
Effectivement, BO vise l’utilisateur de base, totalement inculte en SQL, à le rendre indépendant du service informatique qui n’a plus à lui préparer requêtes et tableaux même s’il doit concevoir l’univers. Évidemment, dans les cas un peu tordus réclamant acharnement, sens logique ou compréhension des subtilités du produit, le rapport atterrit toujours à l’informatique ou chez un consultant.
Il existe deux types d’objets principaux dans l’univers :
- les indicateurs : en gros, ce qui se somme (montants, nombre de clients...) et ce qui s’en déduit (taux, moyennes, extrêmes...) ;
- les dimensions : le reste (dates, lieux, produits, gammes, clients, types, propriétés et statuts divers...), regroupés en plusieurs niveaux plus ou moins hiérarchiques.
Le tableau indépendant ; la notion de contexte de calcul
En voyant (très succintement) JasperReports, un des concurrents libres, j’ai eu l’impression de revenir dix ans en arrière, sur Access ou Oracle Reports, avec une requête tapée à la mimine servant de base au rapport, un affichage ligne à ligne et des sommes calculées à coup de variables incrémentées.
BO par contre considère que l’on peut poser un tableau n’importe où dans la page et que les objets (issus de l’univers) qui y sont jetés se calculent en fonction de leur contexte, c’est-à-dire de leur position dans ce tableau (corps, pied de page, pied de rupture...), et des filtres ou sections de page où se situe ce tableau.
Prenons un tableau de base de l’univers de démonstration (une agence de voyages) : 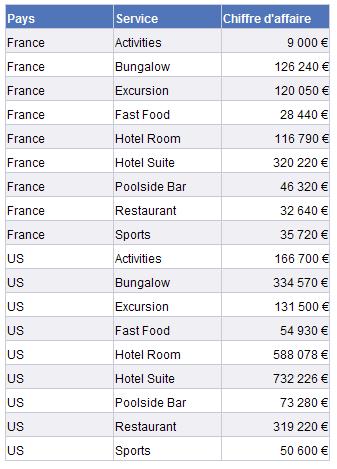 Je copie un tableau plein de colonnes (
Je copie un tableau plein de colonnes (Ctrl et déplacement) puis j’en enlève des dimensions : les chiffres s’agrègent automatiquement. 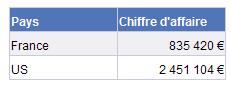
Les cellules des tableaux se remplacent, s’échangent par glisser-déplacer, c’est la partie la plus agréable — voire impressionnante — du développement de rapports. Et en deux clics (littéralement) on rajoute une somme ou une répartition par pourcentage.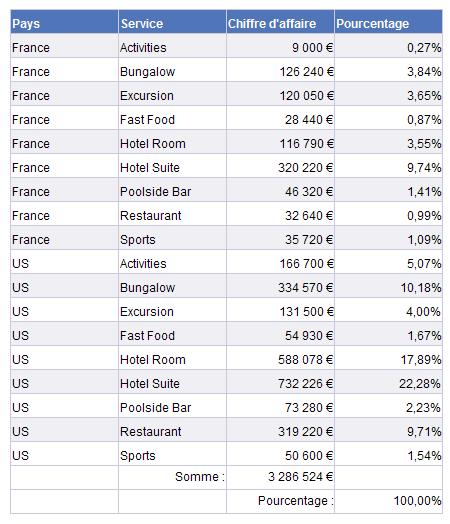
S’ajoutent ensuite les filtres. Dans un tableau des ventes par pays on peut choisir de n’en afficher que certains, nommément comme [Pays]=France, selon un critère du type [Chiffre d’affaire] > 100000 €, voire en ne demandant que le « top 10 ». Les totaux de bas de tableau tiennent compte de ce filtre.
Un clic droit, et ce tableau peut devenir un graphique (qui est juste une forme particulière de tableau[4]). Là aussi les filtrages, ajouts ou suppression d’objets peuvent se faire à volonté.
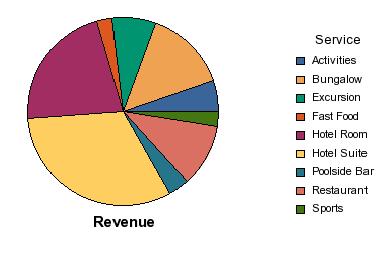

Malheureusement le jeu de tableaux offerts par BO est relativement pauvre au-delà des classiques camemberts et barres empilées. Une simple pyramide des âges d’une population est un petit projet. Par rapport à Visualcomplexity, Worldmapper ou Gapminder, BO retarde de deux générations. Même la cartographie est absente (il y a des produits séparés pour cela).
Les ruptures offrent tout ce qu’on peut désirer comme pieds de tableaux, agrégations intermédiaires, etc. Et j’utilise énormément les sections de page : elles permettent par exemple de reproduire le même jeu de tableaux, libellés, graphiques... en fonction d’un paramètre (ce qui donne une page par service par exemple).
Variables
Les variables (des formules de calcul entre les différents objets) diffèrent d’Excel : elles ne font pas référence à des cellules mais aux objets du tableau.
Exemple : On définit [CA par client] par [Chiffre d'affaire]/[Nombre clients]. On obtient donc un nouvel objet que l’on pourra rajouter dans n’importe quel tableau.
Ce nouvel objet sera lui calculé en mémoire, la base n’est pas impliquée. Avec les machines de bureau actuelles, calculer plein de choses dans le document est souvent plus simple et rapide que de le faire faire par la base de données.
Les fonctions disponibles pullulent. Certaines consistent en altération du contexte, par exemple pour récupérer une donnée qui n’est pas de même niveau d’agrégation (par exemple un pourcentage par rapport au total du tableau =[Indicateur] / [Indicateur] Dans Bloc. Très pratique une fois maîtrisées les formules pour certains clients qui ont des règles de calcul chinoises.
Hélas les variables doivent être recréées dans chaque document. L’utilisateur ne peut les mutualiser. L’univers ne peut les accueillir non plus, il ne sert qu’à traduire les objets prédéfinis en SQL. On peut vouloir rajouter plein d’objets précalculés dans l’univers, mais dès qu’il s’agit de taux et d’objets difficilement agrégeables, les limites du produit apparaissent[5]. Franchement, si je devais rajouter une fonctionnalité dans BO, c’est la possibilité de mettre du code de document Webi (le code des variables) dans des objets de l’univers[6].
Soyons juste, j’ai vu des bugs hallucinants à base de calculs de sommes cumulatives d’objets issus de plusieurs requêtes. Ou encore, des choses incompréhensibles à cause de nombreuses requêtes jointes dans le document via des clés incomplètes (du doublonnage a tendance à apparaître). Au moins est-on dans un domaine très tordu.
Autres points forts
Cerises sur le gâteau :
- BO sait automatiquement prendre en compte des tables d’agrégats précalculées.
Par exemple, soient une table des ventes par jour, et une autre par mois. Il « suffit » d’indiquer dans l’univers dans la définition de chaque indicateur que les deux possibilités existent (au lieu deVENTES.CAon indiquera@Aggregate_Aware(VENTES_MOIS.CA, VENTES_SEMAINE.CA, VENTES.CA)). BO saura choisir la table en fonction des clés disponibles et des objets qu’on lui aura indiqué comme « non compatibles » avec les tables agrégées. Il est dommage que le système des hiérarchies ne soit pas assez fin et automatisé pour trouver les incompatibilités tout seul...
- BO sait gérer des hiérarchies de dimensions (Région/Département/Ville ou Secteur/Gamme/Produit/Référence...) ce qui est la base du mode d’affichage Exploration.
Les gens du contrôle de gestion adorent « zoomer », c’est-à-dire partir d’un tableau par année/pays, cliquer simplement dedans pour chercher les anomalies, descendre en quelques secondes au niveau année/magasin, puis semaine/rayon, et remonter tout aussi vite à semaine/pays.
- BO sait générer plusieurs requêtes séparées quand plusieurs indicateurs viennent de tables différentes. Et il semble que la concurrence ait un sérieux retard là-dessus.
Avec une table des ventes par magasin et une autre des surfaces par magasin (soit deux tables de faits dans un système décisionnel), BO génère deux requêtes (sans jointure externe), effectue en mémoire la jointure (cette fois doublement externe !), et crée un tableau avec magasin, ventes et surface, permettant toutes les astuces d’affichage ou le calcul d’un simple ratio des ventes/m².
En théorie, une seule requête pourrait suffire (et c’est ce qui se passe si les indicateurs viennent de la même table), mais le problème des dimensions pas forcément communes rend le problème parfois... intéressant.
Si les informations viennent carrément de deux bases de données différentes (deux univers), l’utilisateur doit faire les deux requêtes lui-même (BO ne peut pas savoir que fonctionnellement ce sont des choses voisines), mais une fois les jointures indiquées manuellement, BO se débrouille aussi bien avec deux univers (deux bases même) qu’avec un seul.
Évidemment, le diable est dans le détail, et si les bases mathématiques et logiques sont solides, les pièges abondent pour les concepteurs d’univers. L’expert en SQL peut soupirer : dans certains cas il ferait mieux de réécrire les requêtes à la main comme au bon vieux temps ; il s’agit en général d’agrégats tordus qu’un ETL peut parfaitement calculer aussi. (Le problème se déplace alors sur le terrain de « ai-je besoin d’un ETL pour alimenter mes tables ? » ce qui n'est pas le sujet ici mais je me pose parfois la question[7].)
Gadgets supplémentaires
À part Web Intelligence, le système de requêtage décrit ci-dessus, avec trois éditeurs différents (!), la suite de BO offre vend :
- un portail web assez lourd où iront vivre les documents ;
- toute une infrastructure de sécurité à base de « référentiel », très très très fine, jusqu’à l’absurde, pleine de bugs subtils dans les mises à jour de version ;
- tout un système de distribution : la mise à jour quotidienne/mensuelle... d’un document peut être envoyée comme PDF, Excel... par mail, FTP... à beaucoup de monde ;
- un système de web services , terme très à la mode, mais c’en est la première utilisation massive efficace que je vois : un bout de tableau ou un graphique issu d’un document extrêmement travaillé plein de formules devient une simple source de données XML réutilisable ; des produits externes utilisent cette technique pour s’interfacer avec BO ;
- un plugin pour Office qui permet de baser des tableaux Excel ou des animations Powerpoint à des morceaux de documents Webi : les données se rafraîchissent directement dans Excel[8] ;
- des widgets, totalement gadgets, pour avoir un graphique qui se met à jour régulièrement en fond d’écran ;
- plein d’autres trucs que je ne nommerais car 1) je les connais mal ou pas du tout et 2) ils changent souvent de nom entre deux versions !
Évidemment tout cela est propriétaire en diable, et coûte les yeux de la tête (je rappelle qu’on parle d’un produit de l’équivalent français de Microsoft ou Oracle, racheté par SAP, hein).
Bref
Si le travail préparatoire a été bien fait, c’est-à-dire si l’univers permet bien de tout croiser, que des tables d’agrégat sont en place pour optimiser, c’est-à-dire si une alimentation de datawarehouse digne de ce nom est en place (dénormalisée en diable, pas trop « floconnée », indexée à donf’), et que l’on a fait comprendre aux utilisateurs la distinction entre infocentre (pour des listes simples) et datawarehouse (à but décisionnel, non adapté aux listes de clients ou de patients), et que tout le monde a été suffisamment formé sur ces outils et cherche à les comprendre, alors BO se révèle un super outil...
Pour plus de détails, voir par exemple ce Powerpoint pas mal fait.
Notes
[1] Il faudra tout de même y plonger pour désinstaller complètement le Tomcat inclus dans BO.
[2] On notera que pour une fois je vais dire du bien d’un produit SAP, occasion probablement unique dans l’histoire de l’humanité.
[3] Qui, comme tout développeur sait, générera plus d’attention, de remarques, et coûtera plus de temps, que tous les chiffres du tableau.
[4] On dit « bloc » pour désigner un tableau ou un graphique.
[5] Plus en détail : pour les taux, moyennes, décomptes, XI 3 a introduit les « indicateurs intelligents », qui peuvent être agrégés au niveau de la base : la requête SQL est réécrite à chaque changement de contexte de calcul (dans une colonne, un pied de tableau, de page...). C’est une avancée, mais limitée : dès que des opérations ou des filtres s’effectuent sur un tableau, BO ne sait pas les retraduire en SQL, et l’indicateur agrégé devient indisponible. De plus, ce système multiplie les lourdes requêtes à la base (BO semble ignorer la syntaxe du ROLLUP et autres finesses d’Oracle, et crée un ordre SQL par niveau d’agrégation...). Les indicateurs intelligents ne résolvent pas non plus d’autres difficultés : par exemple, en décisionnel, un ratio de deux indicateurs issus de deux étoiles différentes ne pourra jamais s’exprimer directement en SQL car chaque indicateur vient d’une requête différente, et BO fait la jointure en mémoire, pas dans le SQL (on peut se débrouiller en rajoutant une étoile faite juste pour cela, mais ça fait un « contexte » de plus à maintenir dans l’univers). Pour un autre aperçu des indicateurs intelligents, voir par exemple ici
[6] En laissant de côté le problème des performances qui oblige à d’autres compromis, je reste donc sur l’idée que la solution définitive est de requêter une seule fois, au plus bas niveau de détail, puis d’effectuer le calcul final en mémoire dans les tableaux, comme BO a toujours su le faire ; mais avec en plus possibilité de définir les variables dans l’univers à partir d’autres objets de cet univers. Si de plus l’analyse de la syntaxe se fait à l’exécution (comme d’ailleurs c’est le cas pour le SQL généré), on pourrait même créer des objets qui en utiliseraient d’autres issus d’autres univers !
[7] Avis express : dans le cas où l’ETL a ses limites en performance (Talend), et qu’on ne manipule pas de bases hétérogènes, un caïd des vues, des fonctions analytiques d’Oracle et du PL/ ou Transact-SQL peut s’avérer un ETL en meatware efficace. (Ajout de 2011 : Quoiqu’avec le temps je suis de plus en plus pro-ETL. Enfin, ça dépend de l’ETL.)
[8] Si BO a un ennemi mortel, c’est Excel : tout le monde le maîtrise ou croit le maîtriser ; les graphiques y sont bien plus fins ; et on peut toujours y caser au chausse-pied des données issues de partout alors que BO exige un certain travail préparatoire. D’un autre coté, la manipulation des données et leur conversion en différents graphiques se fait plus aisément sous BO, et sans le plugin, Excel ne peut être rafraîchi qu’à grand coup d’exports/réimports manuels.


9 réactions
1 De Pierre - 27/05/2010, 11:31
Que la conclusion est pleine de sens !
2 De pertemoune - 19/10/2010, 17:59
bonjour,
merci pour ce site, super riche en informations utiles.
j'ai deux questions pour vous:
1- Les ETL, j'aimerai avoir votre avis, lequel vous choisirez (DI de BO, Talend, Informatica,...).
2- Les sauvegardes nécessaires pour un serveur BO, certains sont pour les fichiers Biar et les autres parlent des FRS et autres fichiers de confige.
merci
3 De Le webmestre - 20/10/2010, 07:19
@pertemoune :
1) ETL : Mon préféré reste ODI (Oracle DI, ancienneement Sunopsis), qui n'a pas de moteur et s'appuie sur les bases SQL, mais il est devenu cher. J'ai des collègues qui aiment beaucoup Talend, on peut tout programmer avec et il est gratuit, mais y a quand même des lacunes pour le peu que j'en ai vu. DI de BO me rappelle de mauvais souvenirs et je connais peu de gens qui l'aiment. Informatica est une Rolls hors de prix, pour les gros volumes (je le déteste pas), je connais des fanatiques.
Certains se contentent de vues et de scripts, ça dépend de l'hétérogénéité des systèmes impliqués.
2) Pour les sauvegardes, faire les deux : l’export par BIAR est le plus sûr et complet, et facilement récupérable ensuite, mais c'est pas ou peu scriptable (un scandale !) ; alors que la copie complète du FRS+du référentiel SQL associé synchrone est sûr, scriptable, mais impose de remonter une instance complète en cas de besoin de récup.
4 De pertemoune - 20/10/2010, 11:28
Merci beaucoup pour ces informations.
Si vous le permettez j'ai encore une question:
Un malin dans ma boite à supprimer :
Des dossiers publiques tel que: Feature Samples
Des univers tel que: Activity
Des connexions tel que : Auditing Connection
Comment pourrais-je les recréer ?
J’ai pensé à une mise à jour de l’installation, mais je ne suis pas sûr que ça fasse l’affaire, ni que ça ne fera pas plus de dégât.
Merci encore.
5 De Le webmestre - 20/10/2010, 21:54
@pertemoune : je parierais qu'il existe des biar quelque part sur le serveur contenant justement ces choses là. A importer. Sinon, récupérer ça d'une deuxième installation parallèle via un biar.
Pour la connexion d'audit, ce sera plus fun. Mais si ça se trouve, c'est juste celle qui est liée à l'univers Activity, pas la « vraie » connexion d'audit définie dans la CCM, donc il suffira de la reparamétrer dans Designer.
6 De Wazt - 15/12/2011, 18:02
Bonjour
merci pour ce super site,
j'ai une questions : Qu’es-que vous pensez de la partie ETL de Microsoft (Sql Server Integration Services 2005-2008) et SSAS 2008 ? par rapport a BO
est-il performant ? ou je devrai passer a BO ?
Merci
7 De Le webmestre - 15/12/2011, 21:09
Je ne connais pas les outils MS (non que je les trouve inintéressants mais je n'ai tout simplement pas le temps). Un collègue m'a juste dit qu'avec SSIS (quelle version ?) il avait dû se rabattre à tout faire exécuter dans la base à coup de SQL. Des ETL il y a pléthore, la concurrence est vaste.
8 De fleurette - 19/03/2013, 16:01
a un moment donner , on parle de plugin qui permet de prendre les rapport BO sur powerpoint , est ce que je peut avoir une piste la dessus svp
9 De Le webmestre - 19/03/2013, 19:50
@fleurette : il s’agit de LiveOffice, plugin pour Office qui permet d'insérer des tableaux (arbitrairement complexes) et des graphiques (pas des documents entiers) dans un document Office (Word, Excel, Powerpoint) et de les rafraîchir d'un clic. On peut mettre à jour une feuille Excel ou un graphique dans Powerpoint comme ça. Il est possible aussi de faire une petite requête sur une univers et de l'insérer dans Excel.
Et en plus ça marche bien.
L'authentification de l'utilisateur auprès de BO se fait via le paramétrage dans Office une fois pour toute.
Techniquement, derrière, ce sont des Web services java.